
De l’importance des tests unitaires et des tests d’intégration
Pouvez-vous facilement faire la distinction entre vos tests unitaires et vos tests d’intégration ? Connaissez-vous la couverture de code pour chaque niveau de test ? Les outils de tests étant versatiles, il est courant que tous les tests soient exécutés ensemble sans discrimination. Votre framework xUnit préféré ne se limite pas aux tests unitaires, et vous l’utilisez sûrement — à raison — pour les tests d’intégration.
Pourtant, il est très utile de distinguer les tests selon leur niveau. Chaque niveau de test offre ses propres avantages et en favoriser un par rapport à l’autre peut avoir des coûts cachés, que ça soit parce qu’une faute n’est pas détectée ou parce qu’elle est détectée trop tard. Surtout, en ne les distinguant pas, vous ne savez pas si un niveau de test est favorisé et si c’est le cas, ce n’est pas une décision consciente mais un fait subi.
Revue des différents niveaux de test
Un niveau de test regroupe des tests qui ont la même portée. Différentes classifications distinguent différents niveaux, mais on trouve généralement les tests unitaires, les tests d’intégration, et les tests système. Les tests système, qui couvrent le programme dans son intégralité, sont habituellement bien distingués des autres tests, je ne les considérerai donc pas ici.
La portée d’un test est l’étendue des modules qu’il couvre. Un module est un composant unitaire du programme qui remplit une fonction précise. Selon les paradigmes de programmation, on trouve différentes notions de module, mais dans le cadre de la programmation orientée objet on considère communément qu’un module correspond à une classe.
Tests unitaires
Les tests unitaires ont une portée limitée à un seul module. L’objectif est de vérifier le comportement du module en isolation, c’est-à-dire que son contrat d’interface est rempli. Il s’agit de test white box : les mécanismes internes du module sont pris en compte pour la conception des tests.
Si un module a des dépendances vers d’autres modules, il est nécessaire de les simuler, par exemple à l’aide de mocks. Un mock est un objet qui reprend l’interface d’une classe, mais dont le comportement est scripté à chaque test. Il permet à la fois de spécifier les valeurs qu’il doit retourner, mais aussi de vérifier les valeurs qu’il reçoit.
Tests d’intégration
Les tests d’intégration ont une portée qui couvrent plusieurs modules. L’objectif est de vérifier la composition de plusieurs module en s’assurant que les interactions n’entraînent pas d’échec. Il s’agit généralement de tests black box : seules les interfaces des différents modules sont considérées lors du test.
Pourquoi distinguer les différents niveaux de test ?
La confusion entre tests unitaires et tests d’intégration est nuisible car elle ne permet pas d’avoir une vision claire de la couverture de code. Si l’indicateur de couverture de code ne fait pas de distinction, un bon score peut cacher une carence en test d’un niveau, voire des deux.
Par exemple, la figure suivante illustre trois scénarios avec une couverture de code de 85%. Dans le scénario A, le code est couvert à 85% par les deux niveaux de test ; dans le scénario B, le code est couvert à 59% par les deux niveaux de test, à 11% par les tests unitaires et à 15% par les test d’intégration ; dans le scénario C le code, est couvert à 63% par les tests unitaires et à 22% par les tests d’intégration, sans intersection.
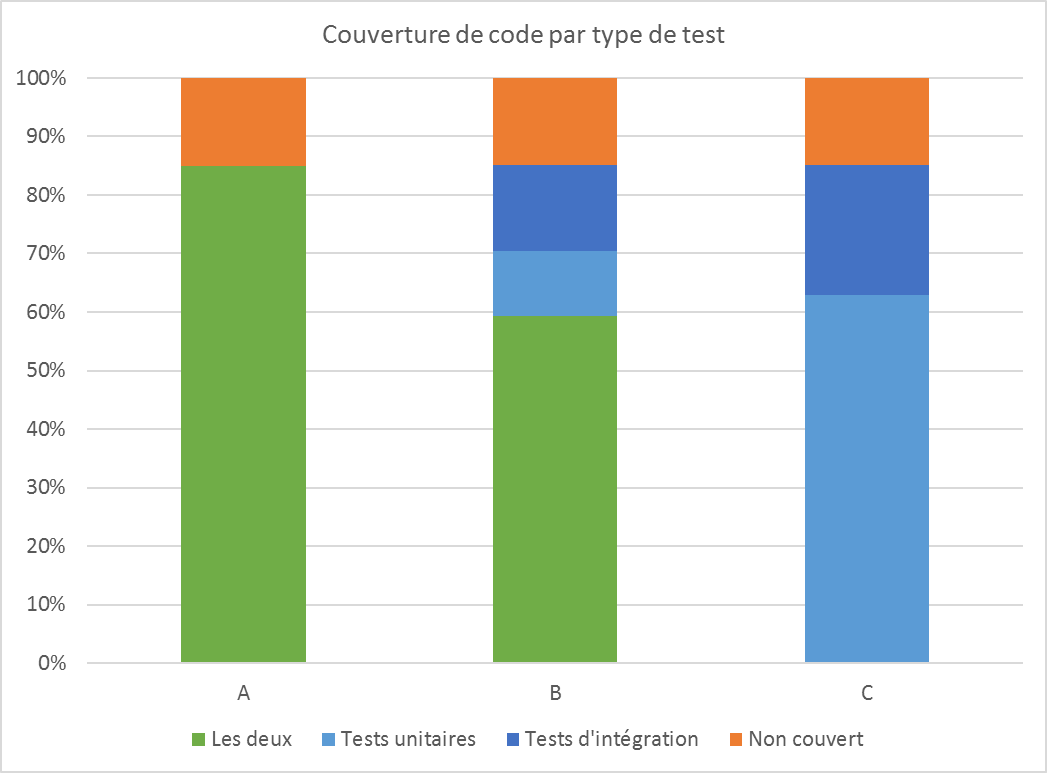
S’il est évident que les trois scénarios ne sont pas équivalents, malgré une couverture unifiée identique, il me faut maintenant vous convaincre que le scénario est A est très favorable et que le scénario C est trompeur.
Échec ou faute ?
Lorsqu’un programme ne fonctionne pas correctement, la faute est l’origine du mauvais fonctionnement, tandis que l’échec est sa manifestation. Par exemple lors de l’écriture d’un fichier, une mauvaise fermeture du flux de sortie peut entraîner une perte de données. La faute est la mauvaise fermeture du flux et l’échec est la perte de données.
Les tests essayent donc de détecter des échecs, dans le but de trouver des fautes dans le programme et de les corriger. Plusieurs échecs peuvent avoir pour origine la même faute et une faute peut ne provoquer aucun échec, auquel cas elle n’est pas détectable par des tests dynamiques.
Les tests unitaires sont-ils suffisants ?
Les tests unitaires vérifiant le comportement de chaque module, n’est-il pas suffisant d’obtenir une couverture totale du code avec des tests unitaires ? Existe-t-il des fautes qui ne peuvent être détectées que par les tests d’intégration ?
Même des modules fonctionnant parfaitement peuvent ne pas interagir correctement ensemble, par exemple, si leurs interfaces ne sont pas totalement compatibles ou si des cas particuliers n’ont pas été anticipés. Il existe donc bien des fautes ne pouvant être détectées par les tests unitaires.
Autre point important, la justesse des tests unitaires dépend des mocks qui simulent le comportement des autres modules. Ces mocks ne reproduisent pas exactement le comportement des modules qu’ils remplacent et peuvent même être défectueux. Les tests d’intégration sont donc indispensables pour assurer que les mocks utilisés lors des tests unitaires sont bien représentatifs des modules qu’ils simulent.
Les tests unitaires sont-ils nécessaires ?
En vérifiant les interactions entre les modules, les tests d’intégration vérifient-ils indirectement le comportement des modules ? Existe-t-il des fautes qui ne peuvent pas être détectées par les tests d’intégration ? Y a-t-il un intérêt aux tests unitaires ?
Les fautes détectables par un test unitaire sont détectables par un test d’intégration ou ne peuvent pas provoquer d’échec lors de l’exécution du programme. Par exemple, prenons un module M1 qui effectue une division par un nombre fourni par un module M2, sans faire de vérification sur ce nombre. Il s’agit d’une faute car le module M1 pourrait ainsi faire une division par zéro. Pour provoquer un échec et détecter la faute avec un test unitaire, il suffit de tester le module M1 avec un mock de M2 qui fournit un zéro. Pour détecter la faute avec un test d’intégration, deux cas sont possibles :
- Il n’est pas possible que M2 fournisse un zéro. Même si la faute est présente, elle ne peut pas provoquer d’échec lors de l’utilisation du programme.
- Il est possible que M2 fournisse un zéro. Dans ce cas il est possible d’écrire un test d’intégration qui détecte la faute.
On pourrait donc conclure que les tests d’intégration sont suffisants : ils détectent plus de fautes que les tests unitaires et les fautes qu’ils ne détectent pas ne peuvent pas provoquer d’échec. Malgré cela, il existe de nombreuses raisons de couvrir le code à l’aide de tests unitaires.
Il est important de s’assurer qu’un module respecte son contrat d’interface, dans le cas où les modules avec lesquels il interagit évoluent. En reprenant l’exemple précédent, si après une évolution il devient possible pour le module M2 de fournir un zéro au module M1, la faute peut alors provoquer un échec. Si un test unitaire l’avait déjà détectée, elle serait déjà connue et probablement corrigée. En ne reposant que sur les tests d’intégration, il faudrait impérativement couvrir ce cas avec un nouveau test lors de l’évolution sous peine que la faute ne soit pas détectée et qu’elle provoque un échec en production.
Les tests unitaires permettent de détecter des fautes plus rapidement. Ils n’ont par définition pas de dépendance forte et peuvent donc être exécutés sur le poste du développeur, contrairement aux tests d’intégration qui peuvent demander un environnement d’exécution spécifique (par exemple, une base de données).
La localisation des fautes est facilitée par les tests unitaires. Lorsqu’un test unitaire échoue, son périmètre étant restreint, il est simple de détecter l’origine de l’échec et la faute peut donc être corrigée rapidement.
Enfin, dans le cadre d’une approche test-driven development, les tests unitaires sont plus appropriés car ils peuvent définir le comportement attendu du module sans interaction non désirée avec le reste du système.
Comment une bonne couverture de code peut cacher une carence en tests
Revenons à nos trois scénarios. Le scénario A est le cas idéal, car le code est bien couvert à la fois par les tests unitaires et par les tests d’intégration. Ainsi, la majorité des fautes sont détectées rapidement dès le développement ou l’évolution des modules, tandis que les fautes plus complexes sont détectées lors des tests d’intégration.
Le scénario B n’est pas aussi idéal que le cas A mais correspond à un compromis acceptable dans beaucoup de cas. Certains modules jouent parfois un rôle d’intégration entre différents services, sans avoir de logique propre, les tests unitaires présentent donc peu d’intérêt. À l’inverse, certains modules n’ont pas de dépendance et il n’y a pas d’intérêt à les couvrir à nouveau avec les tests d’intégration, si les tests unitaires les ont déjà couverts. Il y aura donc toujours une partie du code minimale qui ne sera couverte que par un niveau de test.
Le scénario C est trompeur car l’indicateur de couverture globale par tous les niveaux de test est bon (85%), mais la façon dont cette couverture de code est obtenue n’est pas du tout homogène. Certains modules ne sont couverts que par des tests unitaires et sont donc susceptibles de ne pas fonctionner correctement dans leur environnement de production. D’autres modules ne sont couverts que par des tests d’intégration, ce qui a un coût important lors de l’évolution car les erreurs sont détectées et localisées plus tard.
Conclusion
Il est nécessaire pour avoir une vision précise de l’état des tests d’un programme d’observer la couverture de code pour chaque niveau de test, sans quoi l’indicateur de couverture de code ne sert qu’à discriminer les cas les plus mauvais. Une mauvaise couverture de code indique qu’un gros effort de test est nécessaire ; une bonne couverture de code par tous les niveaux de tests ne permet pas de savoir si un effort est requis.
Une utilisation intelligente des outils de tests est nécessaire pour faire simplement la distinction entre tests unitaires et tests d’intégration. Par exemple, JUnit permet de classer les tests en différentes catégories. Il est ensuite possible de séparer les exécutions des différentes catégories lors de l’intégration continue. Dans le cas de Maven, le plugin Surefire (associé à la phase test) est dédié à l’exécution des tests unitaires et le plugin Failsafe (associé à la phase verify) est dédié à l’exécution des tests d’intégration. Des filtres d’inclusion ou d’exclusion permettent de spécifier quels tests doivent être exécutés par chaque plugin. Le plugin Jacoco fournit la couverture de code pour chaque plugins et donc pour chaque niveau de test.
Les tests unitaires et les tests d’intégrations n’avaient-ils déjà pas de secret pour vous ? J’espère vous avoir apporté des informations utiles dans cet article et reste à votre disposition si vous voulez parler de votre stratégie de tests.